

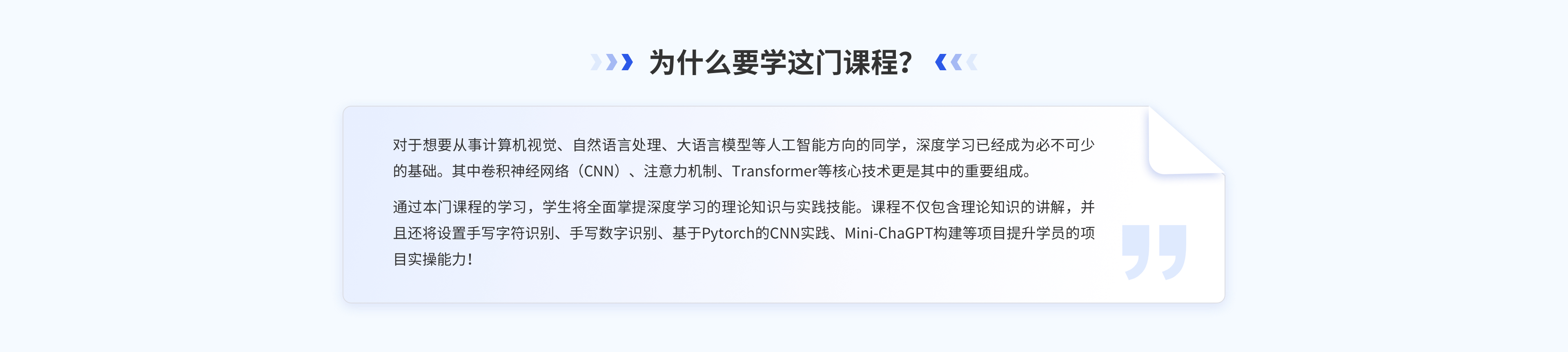
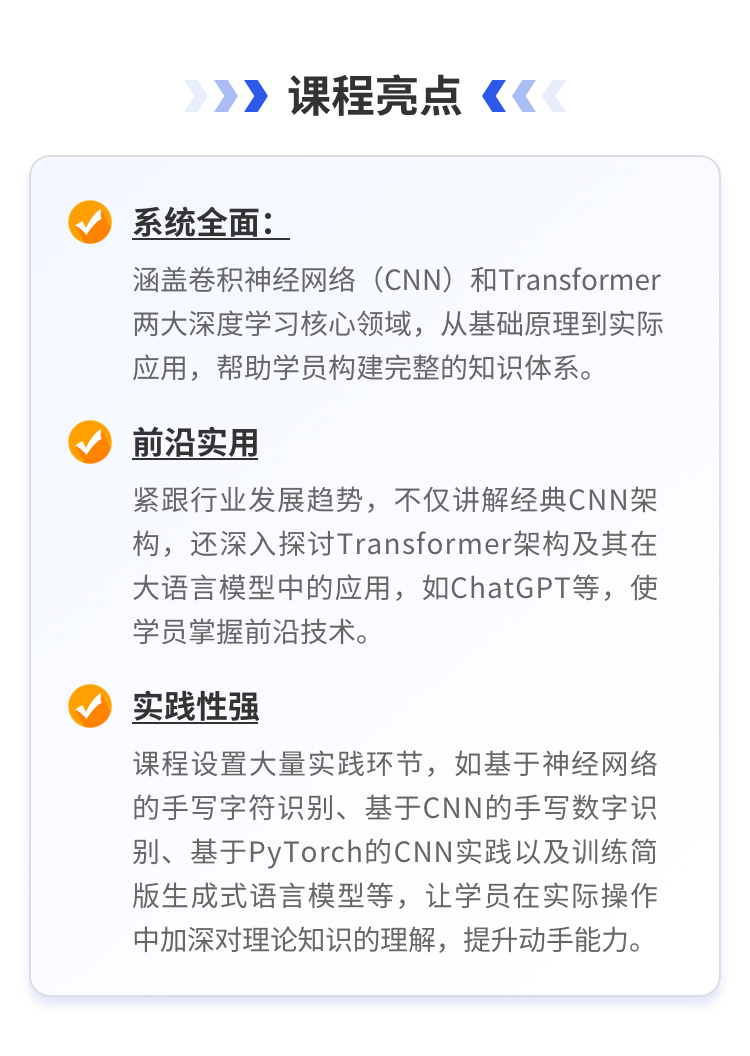
-

学习时长
16小时
-

答疑服务
2个月/专属微信群答疑服务,助教答疑
-

课程有效期
一年/告别拖延,温故知新






- 第1节: 课程直播会议链接汇总
- 1: 直播链接汇总
- 第1章: 开篇:深度学习发展以及应用
- 第1节: 卷积结构与Transformer架构的对比
- 第2节: 注意力机制
- 第3节: Transformer架构详解
- 第4节: 总结
- 第2章: 神经网络入门
- 2: 【课件】神经网络
- 第1节: 逻辑回归
- 3: 【视频】逻辑回归
- 第2节: 感知机
- 4: 【视频】感知机
- 第3节: 什么是神经网络?
- 5: 【视频】神经网络
- 第4节: 神经网络的大招:反向传播
- 6: 【视频】反向传播
- 第5节: 神经网络为什么有效?
- 7: 【视频】激活函数
- 第6节: 实践:基于神经网络的手写字符识别
- 8: 【实践】手写字符识别
- 第3章: 卷积神经网络CNN
- 9: 【课件】卷积神经网络
- 第1节: 什么是卷积及卷积神经网络的核心模块
- 10: 【视频】卷积计算
- 第2节: 卷积神经网络的前向传播
- 11-1: 【视频】CNN网络结构与前向传播
- 11-2: 【资料】A guide to convolution arithmetic
- 11-3: 【资料】Visualizing Convolutional Networks
- 第3节: 卷积神经网络的Loss与反向传播
- 12-1: 【课件】CNN反向传播
- 12-2: 【视频】参数与代价函数
- 12-3: 【视频】反向传播
- 13-1: 【课件】CNN与FCN
- 13-2: 【视频】CNN的参数共享与梯度消失
- 第4节: 实践:基于CNN的手写数字识别
- 14-1: 【视频】CNN手写字符识别实践
- 14-2: 【代码】实践作业代码
- 第4章: 优化算法与参数调节
- 15: 【课件】网络优化
- 第1节: 优化算法: SGD与Adam
- 16: 【视频】优化算法
- 第2节: 参数初始化: Xavier等
- 17: 【视频】参数初始化
- 第3节: 数据预处理: 白化与数据增广
- 18: 【视频】数据预处理和归一化
- 第4节: 正则化
- 19: 【视频】正则化
- 第5章: PyTorch框架介绍
- 20-1: 【课件】Pytorch框架
- 20-2: 【资料】参考资料
- 第1节: Pytorch简介与安装
- 21-1: 【视频】Pytorch简介与安装
- 21-2: 【视频】Windows下安装Pytorch
- 第2节: Pytorch元素介绍
- 22: 【视频】Pytorch元素介绍
- 第3节: Pytorch网络搭建
- 23: 【视频】Pytorch网络搭建
- 第4节: 学习率
- 24-1: 【视频】学习率
- 24-2: 【视频】进阶
- 第5节: 实践:基于PyTorch的CNN实践
- 25: 【资料】基于PyTorch的CNN实践
- 第6章: 从图灵测试到 ChatGPT-NLP 技术发展简史
- 26: 【课件】NLP语言模型技术演进史
- 第1节: 语言的引入
- 27: 【视频】语言模型的引入
- 第2节: 语言模型的进化
- 28: 【视频】语言模型的进化
- 第3节: 预训练语言模型:BERT 和 GPT
- 29: 【视频】预训练语言模型
- 第4节: 大模型的使用模式
- 30: 【视频】大模型的使用模式:Pretrain+fine-tuning与Prompt-Instruct
- 第7章: Transformer 的基础架构-序列到序列-Seq2Seq
- 31: 【课件】Transformer的基本架构-序列到序列-Seq2Seq
- 第1节: Seq2Seq的思想由来
- 32: 【视频】Seq2Seq的思想由来
- 第2节: Seq2Seq 架构详解
- 33: 【视频】Seq2Seq架构详解
- 第3节: Seq2Seq模型实现机器翻译任务
- 34: 【视频】Seq2Seq模型实现机器翻译任务
- 第4节: Seq2Seq 的历史地位与局限
- 35: 【视频】Seq2Seq的局限
- 第8章: Transformer 的核心机制-详解注意力 Attention
- 36-1: 【课件】Transformer的核心机制-注意力Attention
- 36-2: 【代码】Attention
- 第1节: Seq2Seq的局限与Attention的引入
- 37: 【视频】Seq2Seq的局限以及Attention如何解决这种局限
- 第2节: 点积注意力思想
- 38: 【视频】点积注意力思想
- 第3节: 缩放点积注意力
- 39: 【视频】缩放点积注意力
- 第4节: 编码器-解码器注意力
- 40: 【视频】编码器-解码器注意力
- 第5节: 自注意力与多头注意力
- 41: 【视频】自注意力与多头注意力
- 第6节: 注意力中的掩码
- 42: 【视频】注意力中的掩码
- 第7节: 注意力机制总结
- 43: 【视频】总结
- 第9章: Transformer架构详解
- 44: 【课件】Transformer的架构拆解和代码实现
- 第1节: Transformer引入
- 45: 【视频】Transformer引入
- 第2节: Transformer架构概览
- 46: 【视频】Transformer架构概览
- 第3节: 组件:缩放点积注意力与多头注意力
- 47: 【视频】组件:缩放点积注意力与多头注意力
- 第4节: 组件:逐位置前向传播与正弦位置编码
- 48: 【视频】组件:逐位置前向传播与正弦位置编码
- 第5节: 组件:填充位置掩码
- 49: 【视频】组件:填充位置掩码
- 第6节: 组件:编码器与解码器层
- 50: 【视频】组件:编码器与解码器层
- 第7节: 基于Transformer的机器翻译
- 51: 【视频】基于Transformer的机器翻译
- 第10章: 训练你的简版生成式语言模型-GPT
- 52: 【课件】GPT:生成式预训练Transformer
- 第1节: 为什么 GPT 只需要 Decoder
- 53: 【视频】为什么GPT只需要Decoder
- 第2节: 基础模型
- 54: 【视频】基础模型
- 第3节: GPT 架构:逐组件拆解
- 55: 【视频】GPT模型架构
- 第4节: 用 WikiText 训练 Wiki-GPT
- 56-1: 【视频】训练Wiki-GPT
- 56-2: 【视频】程序架构梳理








 官方微信公众号
官方微信公众号

